
1. 데이터 모델
📘 현실세계 정보들을 표현하기 위해 단순화, 추상화하여 체계적으로 표현한 개념적 모형
- 구성요소

구성요소 - 종류
- 개념적 데이터 모델 : 정보모델 ex) E-R 모델
- 논리적 데이터 모델 : 관계 / 계층 / 네트워크 모델로 구분 - 표시 요소
- Structure : 논리적으로 표현된 개체 타입들 간의 관계
- Operation : DB를 조작하는 기본도구
- Constraint : 실제 데이터의 논리적인 제약조건
2. 이상현상(Anomaly) ✨✨
📘 Table에서 종속으로 인해 데이터의 중복이 발생, 이 중복으로 인해 테이블의 조작 시 문제가 발생하는 현상
- 종류
- 삽입 이상 : 데이터 삽입 시, 의도와 다른 원하지 않는 값들로 인해 삽입할 수 없게 되는 현상
- 삭제 이상 : Tuple 삭제 시, 연쇄 삭제가 발생하는 현상
- 갱신이상 : 속성 값 갱신 시, 일부 Tuple의 정보만 갱신되어 정보에 불일치성이 생기는 현상
3. 정규화 (Nomalization) ✨✨✨
📘 Table의 속성들이 상호 종속적인 관계 특성을 이용해 테이블을 무손실 분해하는 과정
- 과정
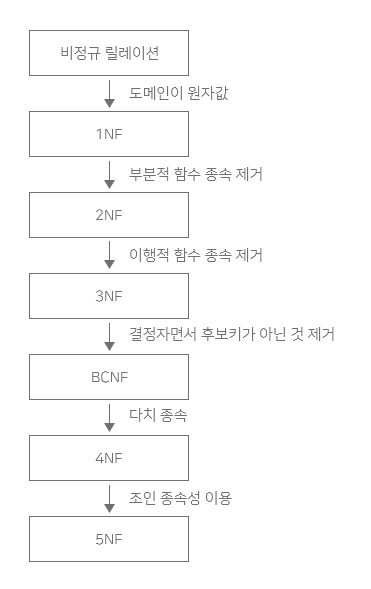
정규화 과정
4. 반정규화 (Denomalization) ✨✨✨
📘 정규화된 데이터 모델을 통합, 중복 분리하는 과정, 의도적으로 정규화 원칙을 위배하는 행위
- 방법
방법 테이블 통합 테이블 분할 중복 테이블 추가 중복 속성 추가 종류 1:1 관계 테이블 통합
1:N 관계테이블 통합
슈퍼타입/서브타입 테이블 통합수평분할
: 레코드(사용빈도기준)를 기준으로 분할추가 방식
집계 테이블의 추가
진행 테이블의 추가
특정 부분만 포함하는 테이블 추가수직분할
: 갱신위주, 크기가 큰 위주, 조회빈도, 보안 필요 순으로 분할고려사항 레코드 증가로 인한 처리량 증가
입력/수정/삭제 규칙 복잡
NotNull, Default, Check 등 제약조건이 있음기본키의 유일성 관리가 힘듦
수행 속도가 느려질 수 있음
데이터 검색을 중점으로 분할 여부 결정테이블의 중복, 속성의 중복 고려
데이터의 일관성, 무결성 유의
SQL 그룹 함수를 이용해 처리
저장공간 낭비
5. 인덱스 설계
📘 데이터 레코드를 빠르게 접근하기 위해 <Key, Value> 쌍으로 구성되는 데이터 구조
- 종류
- 트리 기반 인덱스 : 인덱스를 저장하는 블록들이 트리구조를 이루고 있는 것 ex) B Tree Index, B+ Tree Index
- 비트맵 인덱스 : 인덱스 칼럼의 데이터를 Bit값인 0 or 1로 변환해 인덱스 키로 사용하는 방법
- 함수기반 인덱스 : Column값 대신 특정 함수 또는 수식을 적용해 산출된 값으로 사용하는 방법 ex) B+ Tree Index, Bitmap Index
- 비트맵 조인 인덱스 : 다수의 조인된 객체로 구성된 인덱스
- 도메인 인덱스 : 필요한 인덱스를 직접 만들어 사용
6. View
📘 User에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 기본 테이블로부터 유도된 이름을 가지는 가상 테이블
- 특징
- 물리적으로 구현되어 있지 않음
- 데이터의 논리적 독립성을 제공
- 기본키를 포함한 속성 집합으로 뷰를 구성해야만 삽입/삭제/갱신 연산이 가능함 - 장단점
장점 - 논리적 데이터 독립성 제공
- 사용자의 데이터 관리를 간단히 제공
- 접근제어를 통한 자동 보안 제공단점 - 독립적인 인덱스를 가질 수 없음
- 뷰의 정의 수정 안됨
- 삽입/ 삭제/ 갱신 연산의 제약
7. Cluster
📘 데이터 저장 시 , 데이터 액세스 효율을 향상하기 위해 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법
- 특징
- 데이터 조회 속도 Up, 데이터 입력, 수정, 삭제에 대한 성능 Down
- 분포도가 넓을수록 유리
- 처리 범위가 넓을 경우 ) 단일 테이블 클러스터링
- 조인 발생이 많은 경우 ) 다중 테이블 클러스터링 - 대상 테이블
- 분포도가 넓은 테이블
- 대량의 범위를 자주 조회하는 테이블
- 입력, 수정, 삭제가 자주 발생하지 않는 테이블
- 자주 조인되어 사용되는 테이블
- ORDER BY, GROUP BY, UNION이 빈번한 테이블
정보처리기사 데이터 입출력 구현 요약본입니다😆
'certificate' 카테고리의 다른 글
| [정보처리기사 필기] 애플리케이션 테스트 관리 - 1 (0) | 2022.01.25 |
|---|---|
| [정보처리기사 필기] 화면설계 (0) | 2021.12.17 |
| [정보처리기사 필기] 서버 프로그램 구현 (0) | 2021.12.11 |
| [정보처리기사 필기] 통합구현 (0) | 2021.12.11 |
| [정보처리기사필기] 요구사항 확인 (0) | 2021.12.09 |